AUDIOSEAR.CH: POWERING THE FUTURE OF LISTENING
This post originally appeared on Pop Up Archive’s Audiosear.ch blog.
In 2014, our co-founders — Anne Wootton and Bailey Smith — were very, very busy.
Every day they were commuting from Oakland, CA to 500 Startups’ Mountain View accelerator as they developed Pop Up Archive, a business then in its infancy. They spent their days learning about speech-to-text software and ways of modeling data for audio, pitching their vision that audio was a medium whose parity with text was becoming inevitable. They talked about developing a product that was like Google for all types of audio. Then the podcast “Serial” was released.
Serial was the fastest podcast to reach five million downloads in the iTunes store, and is widely regarded as putting podcasting on the radar of the general public. Anne and Bailey watched Serial develop a huge and passionate following nearly instantly — and the unprecedented binge-listening that followed. They realized their technology could be uniquely applied to the burgeoning new industry of on-demand audio.
Up to that point, Pop Up Archive had made sound searchable for a lot of radio stations and cultural heritage institutions, and as we watched on-demand audio grow we realized there was a lot about the the tools we’d developed that could be applied to podcasts exclusively. We started thinking about how tools to automatically transcribe, search, and extract metadata could help build the future of podcast discovery and listening. From that effort, Audiosear.ch was born.
We knew that effective podcast discovery needed both machine automation (for things like transcription, scalability, and calculating complex relationships between content) and human input (providing intuition, nuance, and strategy). To start shaping our efforts, we generated a bunch of hypotheses about factors that we thought might make audio easier to surface and to contextualize — information both contained in the audio and floating around the web that, if analyzed, could link podcasts together and to other forms of media. Then we ran experiments — so many experiments! — to test, refine, and iterate on these hypotheses.
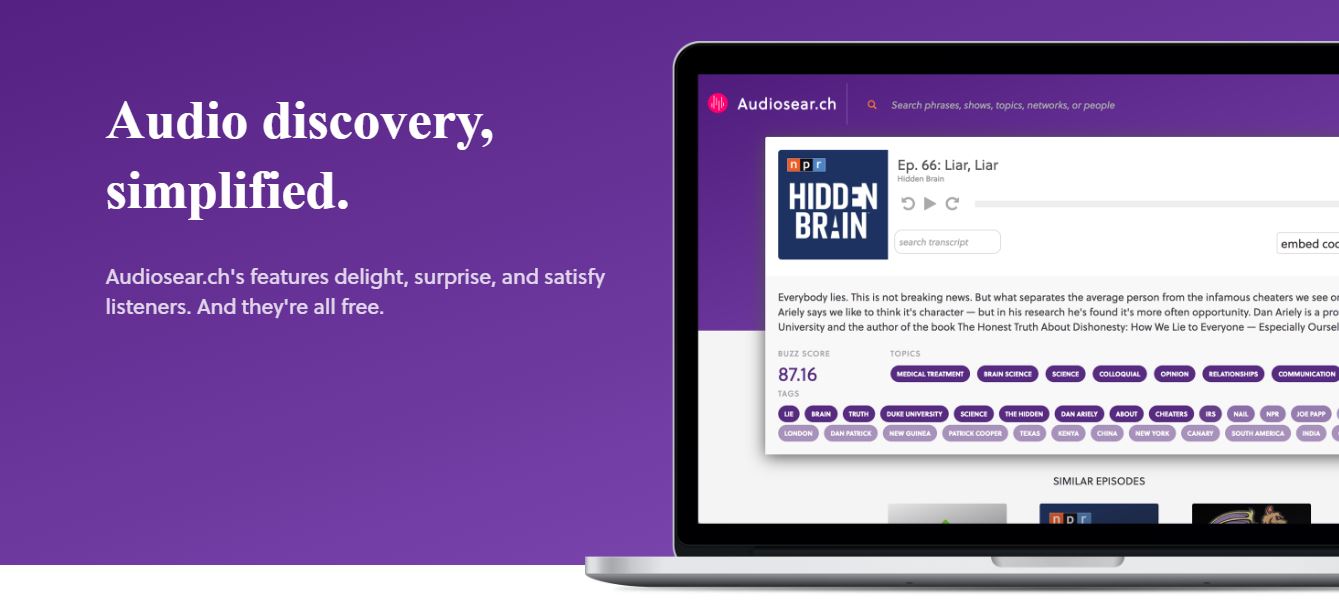
The result is Audiosear.ch: a one-stop intelligence engine for podcasts that provides more —and more sophisticated — discoverability and information about who is listening to what, and how they’re sharing it, than is captured by the iTunes charts.
The development of Audiosear.ch has led to some incredibly cool and unexpected outcomes, such as when we were approached to license our data to streamline ad verification workflows, or when our API helped solve the “cold start” problem for a podcast app recommending new episodes that don’t yet have listening data. We’ve seen users register for audio alerts for everything from sponsorship messages to Tim Ferriss to Justin Bieber. One developer used our API to build an Amazon Alexa skill called Magic Podcast.
As the influx of voice-controlled devices playing a bigger and bigger role in our daily lives, the way we discover audio will continue to change. What if you could ask your phone, car, or Alexa, “Play me a crime podcast that people are buzzing about right now,” or “Play me a 30-minute podcast about extreme sports.” The Audiosear.ch API is driving voice-enabled podcast discovery by delivering results based on how people naturally seek out new content.
We’re excited to share all of the Audiosear.ch features with you, but here are three we’d like to highlight:
- Buzz score
Use buzz score to discover which podcast episodes are being talked about the most. Derived from a number of relevant factors, including social chatter from podcast listeners across the web, this quality rating helps find the best episodes of shows you love — as well as uncover new hidden gems.
Think of topic clusters as a sophisticated discovery tool that’s also really simple. We’ve analyzed thousands of episodes to create topic-based clusters, so you can discover content by topics like “NSFW,” “Death/Disaster,” “Relationships,” “Guns/Police,” and more.
Easily select a favorite audio clip and share it as a short, snappy video on Facebook or Twitter as a short video, allowing you to instantly share with your followers (even those with their sound turned off) the amazing piece of tape you just heard.
Our goal is to build the infrastructure that will power podcast listening experiences of the future. Thus far, it has been a thrilling, challenging, and endlessly surprising experience.
Over the course of the past two years we’ve learned a lot and have been helped along the way by a wide community of people — from our Pop Up Archive customers, to creators and distributors in the on-demand audio world, to ordinary people sharing the shows and episodes they love most. We’re especially excited to see the needs of the industry increasingly coalescing around some of the work that we’ve been doing, whether that’s full-text search of transcripts, entity extraction to enable thematic playlist curation, or more sophisticated measurements, like buzziness, that go beyond downloads and iTunes charts.
Thanks to everyone who has been a part of Audiosear.ch up until now. And to all of our newcomers: welcome! Explore some of our features and, if you’re a developer, jump in and start using our API.
r
-

-
Technology / Article

-
Journalism / Article
Recent Content
-
 Artsarticle ·
Artsarticle · -
 Artsarticle ·
Artsarticle · -
 Community Impactarticle ·
Community Impactarticle ·